Chapter 8 GridFS
A recent addition to mongolite is support for GridFS. A GridFS is a special type of collection for storing binary data such as files. To the user, a GridFS looks very much like a key-value store which supports potentially very large values.
screencast
8.1 Connecting to GridFS
The GridFS API is different from normal Mongo collections. Connecting works similar as with regular mongo() with one important difference: instead of specifying a collection name, we need to set a name prefix:
Under the hood, GridFS stores files in two collections. In the case of prefix = "fs":
fs.chunksstores the binary chunks.fs.filesstores the file metadata.
Hence the prefix identifies the GridFS .chunks and .files data collections that make up the GridFS table.
8.2 GridFS Methods
To get an overview of available methods, print the gridfs object. The methods are described in the ?gridfs manual page.
#> <gridfs>
#> $disconnect(gc = TRUE)
#> $download(name, path = ".")
#> $drop()
#> $find(filter = "{}", options = "{}")
#> $read(name, con = NULL, progress = TRUE)
#> $remove(name)
#> $upload(path, name = basename(path), content_type = NULL, metadata = NULL)
#> $write(con, name, content_type = NULL, metadata = NULL, progress = TRUE)The basic API supports the following operations:
- Write (upload) new files into GridFS
- Read (download) files from GridFS
- Find (list) files in the GridFS
- Delete a file
Note that updating (modifying) files in GridFS is currently unsupported: uploading a file with the same name will generate a new file.
8.3 Read / Write
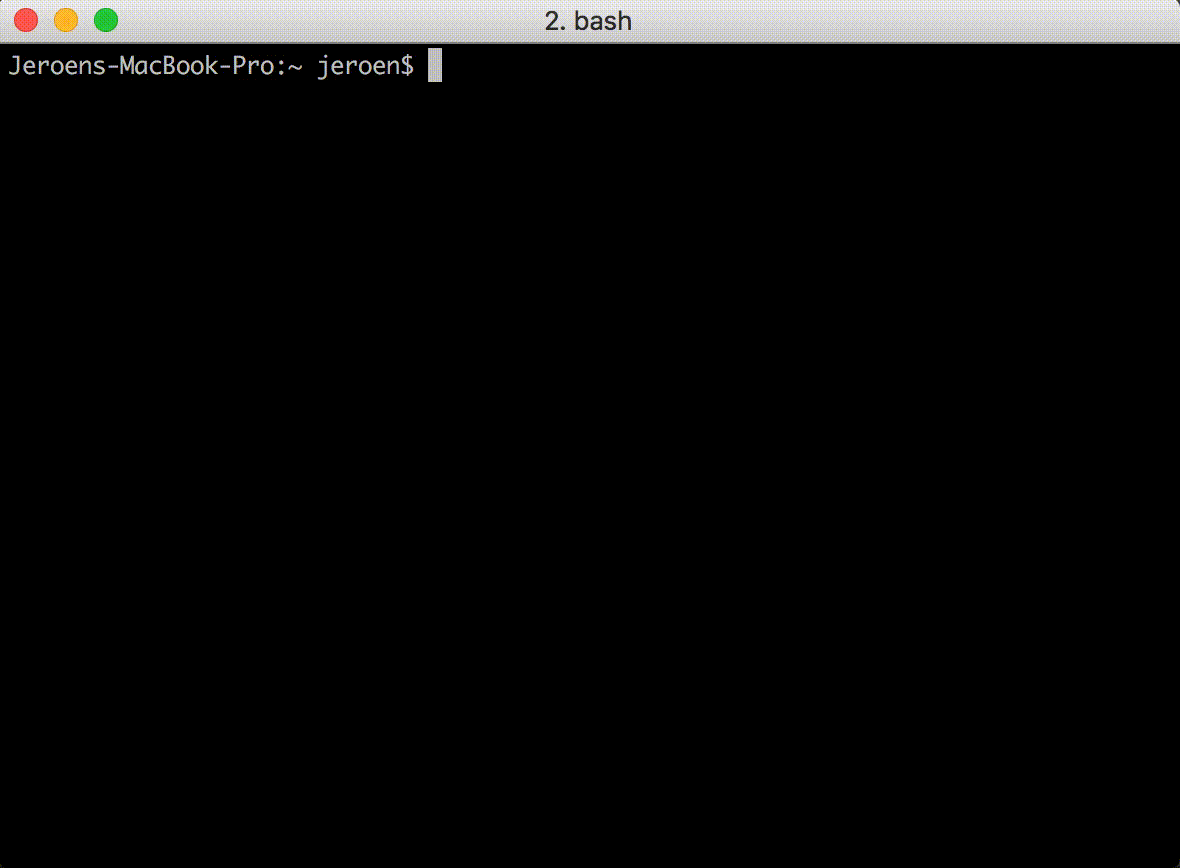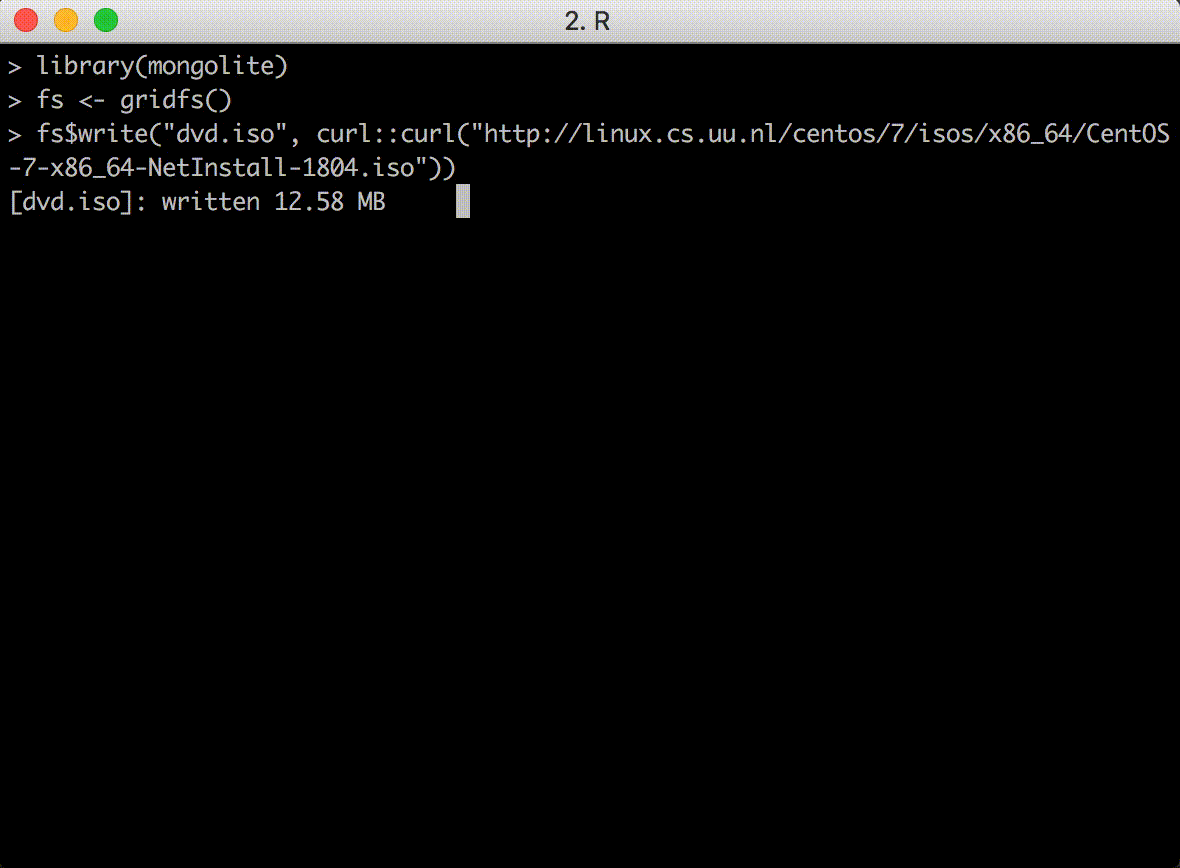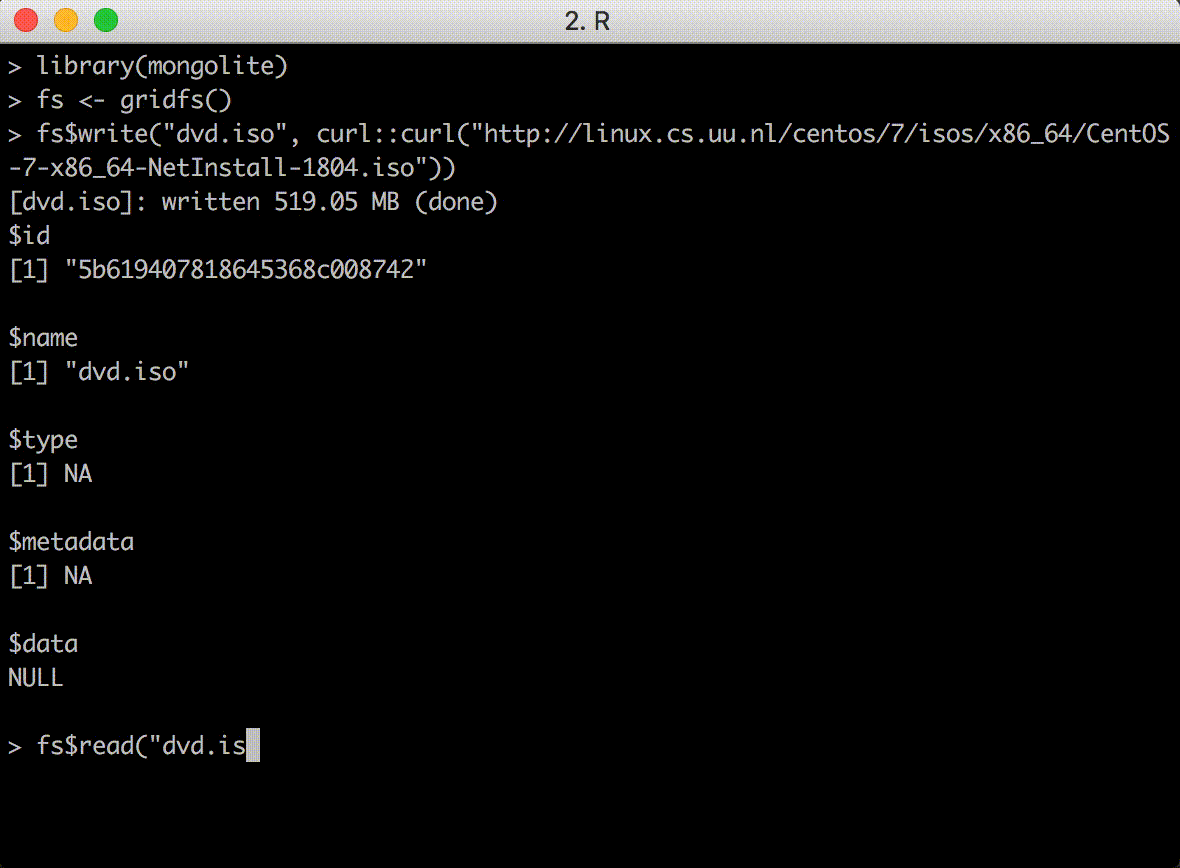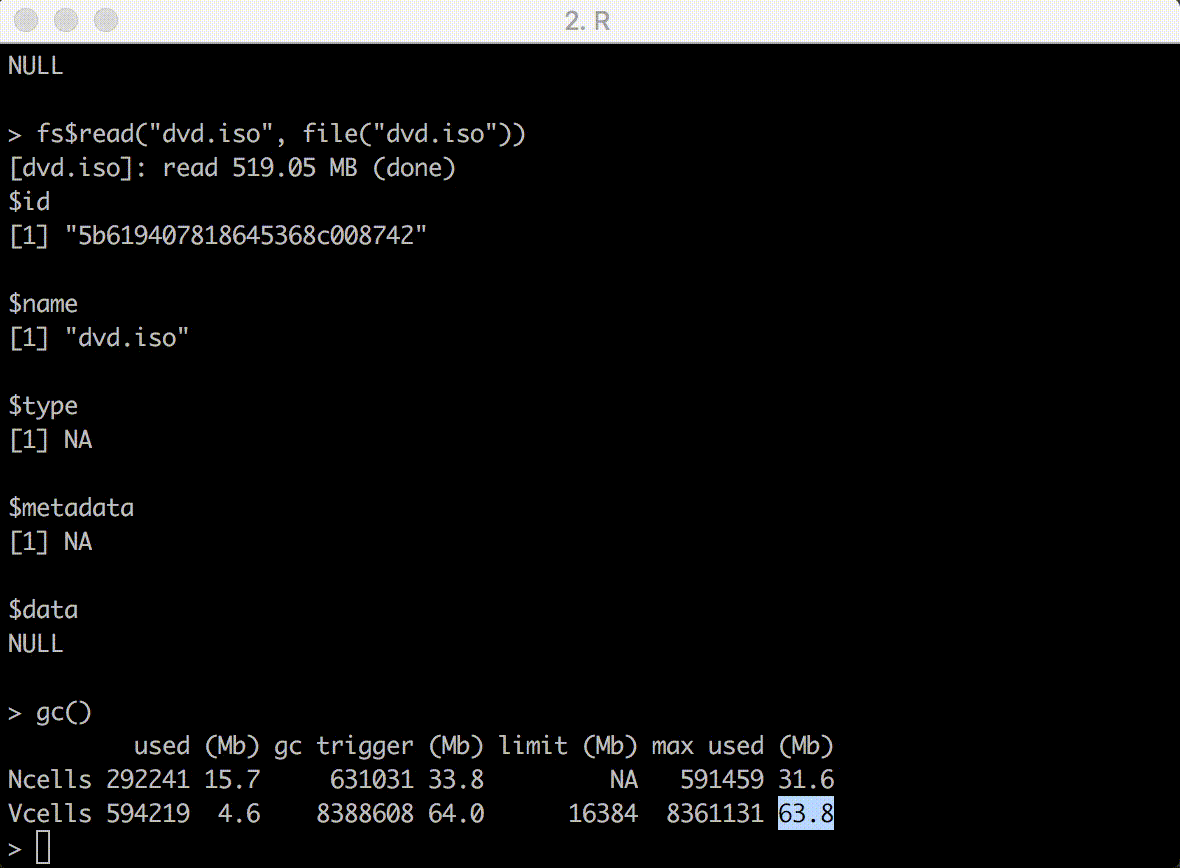
The fs$read() and fs$write() methods send data from/to an R connection, such as a file, socket or url. This is the recommended way to to send/receive data with GridFS. You get a nice progress counter and the transfer can be interrupted if needed.
Both read() and write() methods have a con argument that specifies the input or output connection. You can also pass a string, which is treated as a file path. Here we stream a file from a URL:
# Stream data from a URL into GridFS
con <- url('https://cloud.r-project.org/src/base/R-3/R-3.5.1.tar.gz')
fs$write(con, 'source.tar.gz', progress = FALSE,
metadata = '{"This is" : "just a test"}')#> List of 6
#> $ id : chr "5b6ca17a47a302fe131620dc"
#> $ name : chr "source.tar.gz"
#> $ size : num 29812849
#> $ date : POSIXct[1:1], format: "2018-08-09 22:18:02"
#> $ type : chr NA
#> $ metadata: chr "{ \"This is\" : \"just a test\" }"In addition, for fs$write() you can set con to a raw vector with data to upload.
#> List of 6
#> $ id : chr "5b6ca17d47a302fe131620dd"
#> $ name : chr "mtcars"
#> $ size : num 3798
#> $ date : POSIXct[1:1], format: "2018-08-09 22:18:05"
#> $ type : chr NA
#> $ metadata: chr NAThe fs$find() method shows a list of files:
#> id name size date type metadata
#> 1 5b6ca17a47a302fe131620dc source.tar.gz 29812849 2018-08-09 22:18:02 <NA> { "This is" : "just a test" }
#> 2 5b6ca17d47a302fe131620dd mtcars 3798 2018-08-09 22:18:05 <NA> <NA>We can read the data to disk using fs$read():
# Stream the file from GridFS to disk
out <- fs$read('source.tar.gz', file('source.tar.gz'), progress = FALSE)
file.info('source.tar.gz')$size#> [1] 29812849For fs$read() you can set con to NULL in which case the file will be buffered in memory and returned as a raw vector. This is useful for e.g. unserializing R objects.
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#> Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#> Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#> Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#> Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
#> Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1When done we trash the GridFS:
#> [1] TRUE8.4 Vectorized Upload/Download
The fs$upload() and fs$download() methods provide an alternative API specifically for transferring files between GridFS and your local disk. This API is vectorized so you can transfer many files at once. However transfers cannot be interrupted and will block R until completed. This API is only recommended to upload/download a large number of small files.
# Start a new GridFS and upload all files from this book
mb <- mongolite::gridfs(prefix = 'mongobook')
mb$upload(list.files(".", recursive = TRUE))#> id name size date type metadata
#> 1 5b6ca17d47a302fe131620de _bookdown.yml 89 2018-08-09 22:18:05 <NA> <NA>
#> 2 5b6ca17d47a302fe131620df _build.sh 80 2018-08-09 22:18:05 application/x-sh <NA>
#> 3 5b6ca17d47a302fe131620e0 _output.yml 342 2018-08-09 22:18:05 <NA> <NA>
#> 4 5b6ca17d47a302fe131620e1 01-connecting.Rmd 9135 2018-08-09 22:18:05 text/x-markdown <NA>
#> 5 5b6ca17d47a302fe131620e2 02-queries.Rmd 5998 2018-08-09 22:18:05 text/x-markdown <NA>
#> 6 5b6ca17d47a302fe131620e3 03-insert.Rmd 3121 2018-08-09 22:18:05 text/x-markdown <NA>
#> 7 5b6ca17d47a302fe131620e4 04-export.Rmd 2296 2018-08-09 22:18:05 text/x-markdown <NA>
#> 8 5b6ca17d47a302fe131620e5 05-calculation.Rmd 2622 2018-08-09 22:18:05 text/x-markdown <NA>
#> 9 5b6ca17d47a302fe131620e6 06-commands.Rmd 491 2018-08-09 22:18:05 text/x-markdown <NA>
#> 10 5b6ca17d47a302fe131620e7 07-gridfs.Rmd 4465 2018-08-09 22:18:05 text/x-markdown <NA>
#> 11 5b6ca17d47a302fe131620e8 dump.json 10986497 2018-08-09 22:18:05 application/json <NA>
#> 12 5b6ca17d47a302fe131620e9 flights.bson 79319562 2018-08-09 22:18:05 <NA> <NA>
#> 13 5b6ca17e47a302fe131620ea index.Rmd 3575 2018-08-09 22:18:06 text/x-markdown <NA>
#> 14 5b6ca17e47a302fe131620eb fighist-1.png 48856 2018-08-09 22:18:06 image/png <NA>
#> path
#> 1 /Users/jeroen/workspace/mongobook/mongobook/_bookdown.yml
#> 2 /Users/jeroen/workspace/mongobook/mongobook/_build.sh
#> 3 /Users/jeroen/workspace/mongobook/mongobook/_output.yml
#> 4 /Users/jeroen/workspace/mongobook/mongobook/01-connecting.Rmd
#> 5 /Users/jeroen/workspace/mongobook/mongobook/02-queries.Rmd
#> 6 /Users/jeroen/workspace/mongobook/mongobook/03-insert.Rmd
#> 7 /Users/jeroen/workspace/mongobook/mongobook/04-export.Rmd
#> 8 /Users/jeroen/workspace/mongobook/mongobook/05-calculation.Rmd
#> 9 /Users/jeroen/workspace/mongobook/mongobook/06-commands.Rmd
#> 10 /Users/jeroen/workspace/mongobook/mongobook/07-gridfs.Rmd
#> 11 /Users/jeroen/workspace/mongobook/mongobook/dump.json
#> 12 /Users/jeroen/workspace/mongobook/mongobook/flights.bson
#> 13 /Users/jeroen/workspace/mongobook/mongobook/index.Rmd
#> 14 /Users/jeroen/workspace/mongobook/mongobook/mongobook_files/figure-html/fighist-1.png
#> [ reached getOption("max.print") -- omitted 6 rows ]In the same way we can download all files in one command:
#> id name size date type metadata
#> 1 5b6ca17d47a302fe131620de _bookdown.yml 89 2018-08-09 22:18:05 <NA> <NA>
#> 2 5b6ca17d47a302fe131620df _build.sh 80 2018-08-09 22:18:05 application/x-sh <NA>
#> 3 5b6ca17d47a302fe131620e0 _output.yml 342 2018-08-09 22:18:05 <NA> <NA>
#> 4 5b6ca17d47a302fe131620e1 01-connecting.Rmd 9135 2018-08-09 22:18:05 text/x-markdown <NA>
#> 5 5b6ca17d47a302fe131620e2 02-queries.Rmd 5998 2018-08-09 22:18:05 text/x-markdown <NA>
#> 6 5b6ca17d47a302fe131620e3 03-insert.Rmd 3121 2018-08-09 22:18:05 text/x-markdown <NA>
#> 7 5b6ca17d47a302fe131620e4 04-export.Rmd 2296 2018-08-09 22:18:05 text/x-markdown <NA>
#> 8 5b6ca17d47a302fe131620e5 05-calculation.Rmd 2622 2018-08-09 22:18:05 text/x-markdown <NA>
#> 9 5b6ca17d47a302fe131620e6 06-commands.Rmd 491 2018-08-09 22:18:05 text/x-markdown <NA>
#> 10 5b6ca17d47a302fe131620e7 07-gridfs.Rmd 4465 2018-08-09 22:18:05 text/x-markdown <NA>
#> 11 5b6ca17d47a302fe131620e8 dump.json 10986497 2018-08-09 22:18:05 application/json <NA>
#> 12 5b6ca17d47a302fe131620e9 flights.bson 79319562 2018-08-09 22:18:05 <NA> <NA>
#> 13 5b6ca17e47a302fe131620ea index.Rmd 3575 2018-08-09 22:18:06 text/x-markdown <NA>
#> 14 5b6ca17e47a302fe131620eb fighist-1.png 48856 2018-08-09 22:18:06 image/png <NA>
#> path
#> 1 outputfiles/_bookdown.yml
#> 2 outputfiles/_build.sh
#> 3 outputfiles/_output.yml
#> 4 outputfiles/01-connecting.Rmd
#> 5 outputfiles/02-queries.Rmd
#> 6 outputfiles/03-insert.Rmd
#> 7 outputfiles/04-export.Rmd
#> 8 outputfiles/05-calculation.Rmd
#> 9 outputfiles/06-commands.Rmd
#> 10 outputfiles/07-gridfs.Rmd
#> 11 outputfiles/dump.json
#> 12 outputfiles/flights.bson
#> 13 outputfiles/index.Rmd
#> 14 outputfiles/fighist-1.png
#> [ reached getOption("max.print") -- omitted 6 rows ]#> [1] "_bookdown.yml" "_build.sh" "_output.yml" "01-connecting.Rmd" "02-queries.Rmd"
#> [6] "03-insert.Rmd" "04-export.Rmd" "05-calculation.Rmd" "06-commands.Rmd" "07-gridfs.Rmd"
#> [11] "dump.json" "fighist-1.png" "figstats-1.png" "flights.bson" "index.Rmd"
#> [16] "mongobook.Rmd" "mongobook.Rproj" "mtcars.json" "style.css" "toc.css"This makes a convenient way to store an large set of files into GridFS.
8.5 Select by ID
If your GridFS contains duplicate filenames, you can use their unique ID to refer to them:
#> id name size date type metadata
#> 1 5b6ca17d47a302fe131620de _bookdown.yml 89 2018-08-09 22:18:05 <NA> <NA>
#> 2 5b6ca17d47a302fe131620df _build.sh 80 2018-08-09 22:18:05 application/x-sh <NA>
#> 3 5b6ca17d47a302fe131620e0 _output.yml 342 2018-08-09 22:18:05 <NA> <NA>
#> 4 5b6ca17d47a302fe131620e1 01-connecting.Rmd 9135 2018-08-09 22:18:05 text/x-markdown <NA>
#> 5 5b6ca17d47a302fe131620e2 02-queries.Rmd 5998 2018-08-09 22:18:05 text/x-markdown <NA>
#> 6 5b6ca17d47a302fe131620e3 03-insert.Rmd 3121 2018-08-09 22:18:05 text/x-markdown <NA>To select a file by it’s id, prefix the name with “id:” for example:
#> [1] "id:5b6ca17d47a302fe131620de"#>
[{ "_id" : { "$oid" : "5b6ca17d47a302fe131620de" } }]: read 89 B (100%)
[{ "_id" : { "$oid" : "5b6ca17d47a302fe131620de" } }]: read 89 B (done)#> List of 6
#> $ id : chr "5b6ca17d47a302fe131620de"
#> $ name : chr "_bookdown.yml"
#> $ size : num 89
#> $ date : POSIXct[1:1], format: "2018-08-09 22:18:05"
#> $ type : chr NA
#> $ metadata: chr NASame for download() and remove():
#> id name size date type metadata
#> 1 5b6ca17d47a302fe131620de _bookdown.yml 89 2018-08-09 22:18:05 <NA> <NA>#> [1] TRUE